BGP routing to containers in BlaBlaCar

Context
Until now, routing of public traffic to our front servers was done via some particular servers, called load-balancers(LB) in our infrastructure. These servers were built with nginx for SSL-offloading, varnish for the reverse-proxy part, and ExaBGP for the communication with our BGP routers.
Our infrastructure’s move to containers with rkt has lead us to re-consider the cooperation of these components.
Existing infrastructure
For the current design, I was inspired by Vincent Bernat’s excellent post: High availability with ExaBGP
When applied to our own infra, it looked like this:
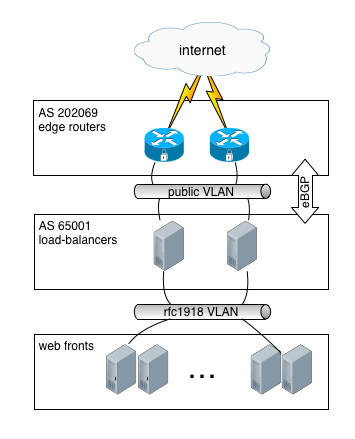
Each of the load-balancers is running ExaBGP, which is talking with BGP routers. Config example of one of them:
group neighbors {
neighbor 91.238.131.1 {
router-id 91.238.131.5;
local-address 91.238.131.5;
local-as 65001;
peer-as 202069;
}
neighbor 91.238.131.2 {
router-id 91.238.131.5;
local-address 91.238.131.5;
local-as 65001;
peer-as 202069;
}
}With ExaBGP, we also use its healthcheck plugin, which is continuously testing the resource and, if available, annoucning some VIPs:
process healthcheck-apex {
run /etc/exabgp/processes/healthcheck.py --config /etc/exabgp/healthcheck-apex.conf;
}Let’s check healthcheck-apex.conf in detail:
name = apex
interval = 10
fast-interval = 1
command = curl -sf http://127.0.0.1/healthcheck
ip = 91.238.131.166
ip = 91.238.131.167Second LB’s config looks the same, except the VIPs order:
name = apex
interval = 10
fast-interval = 1
command = curl -sf http://127.0.0.1/healthcheck
ip = 91.238.131.167
ip = 91.238.131.166Why this difference ?
It is connected with the way healthcheck works. For each specified VIP, healthcheck makes an announce to ExaBGP, increasing the med attribute by 1. Example on the first LB:
announce route 91.238.131.166/32 next-hop self med 100
announce route 91.238.131.167/32 next-hop self med 101
It means that each LB is announcing the same VIP set, but with a different weight (using med). As a consequence, BGP routers only route traffic for a particular VIP to a single LB.
Just publish these 2 VIPs into DNS for a particular service (apex here), and you’ll obtain a highly available service.
In case of LB failure, it won’t announce its VIPs anymore. Fortunately, BGP routers know at least another route, towards the second LB, so the service keeps working.
Behaviour with containers
In our new datacenter, we are using rkt containers exclusively, as the basic run unit. Every servers are the same, and they run only a single operating system: CoreOS. This infrastructure is massively automated.
From a network point of view, we used this huge change as an opportunity to switch from a L2 to a L3 model, since we don’t need VLANs anymore. Network isolation is reached using ACLs that are pre-generated and deployed onto CoreOS (the same principle as AWS security groups).
Therefore, we setup BGP on each level, from edge routers to top-of-rack (ToR) switches. It looks like this:
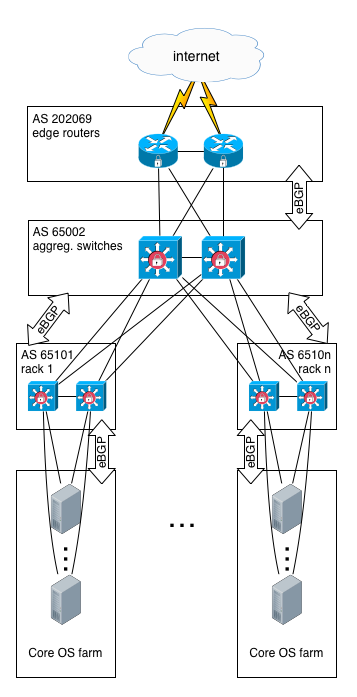
Then, in each rack, a single CoreOS server is dedicated to load-balancing. It runs a set of containers (called a pod), and this pod is in charge of running ExaBGP, and announce the VIPs handled by this LB.
ExaBGP config sample on rack #1:
group neighbors {
neighbor 10.20.151.129 {
router-id 10.20.151.147;
local-address 10.20.151.147;
local-as 65147;
peer-as 65101;
}
neighbor 10.20.151.130 {
router-id 10.20.151.147;
local-address 10.20.151.147;
local-as 65147;
peer-as 65101;
}
}Problem encountered
When running our first tests, we encountered a problem pretty fast: for a particular service, whatever the number of LB instances was, only one LB was receiving all of the traffic.
After troubleshooting, it appears that the behaviour was as expected. Each LB was announcing the same VIPs, with a different med, and this med was taken into account by the correspondig ToR.
However, the VIP, when re-announced by the ToR to the upper level (aggregation switches), was loosing its med attribute. This behaviour is by design in BGP when ASN changes: med is a non-transitive attribute
Edge routers were knowing different routes, but with different as-paths (non-eligble to bgp-multipath, thus). So they chose the older route, which is online with the behaviour seen: only a single LB (the first started) receives all of the traffic.
Workarounds
We though about several workarounds:
- bgp multihop
- route server
- BGP community values
- ExaZK
BGP multihop
First idea we had: connect the LBs directly to aggregation switches, and not to ToR. We had to use multihop mode of BGP:
router bgp 65002
neighbor a.b.c.d remote-as 651xx
ebgp-multihop 2
Unfortunately, using this solution, next-hop attribute for the received routes was unknown in the IGP of the aggregation layer. Thus, the route was not inserted into RIB.
Route server
Next idea was to use a route server. Instead talking to ToR, the LBs would have to talk to aggregation layer in route-server mode. Here again, we were luckless: our aggregation switches are Cisco Nexus 3064, and their implementation of BGP does not include support for the route-server-client directive.
BGP community
Another idea: rather than using a non-transitive attribute like med is, what about using a transitive one: community. Despite this idea was pretty sexy, we dropped it because:
- high complexity of
route-mapsthat we would have to implement on the aggregation layer, to handle this community values properly. - need to modify the source-code of
healthcheck, in order to usecommunityrather thanmed
ExaZK
Since the best idea we had implied to modify healthcheck’s source code, we though it would be worth writing our own plugin, and to connect it directly to our service directory.
Indeed, in our container oriented infrastructure, orchestration of the containers (instancing, quantity, deployment …) is highly relying on ZooKeeper.
It appeared to us that ExaBGP should speak directly with ZooKeeper to determine what to announce to BGP routers. Accordingly, we chose to code this plugin: ExaZK
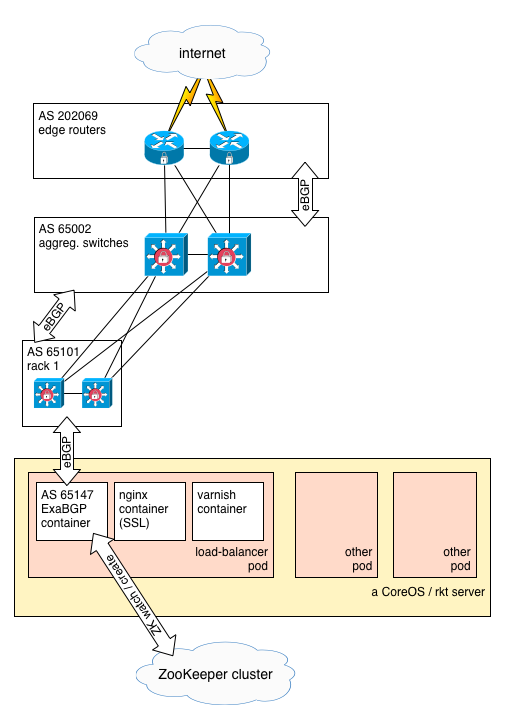
Principle is:
- regarding a particular service, say apex, we run 3 LB pods, on 3 different CoreOS servers, located in 3 different racks
- each of these pods is running
ExaBGPwithExaZK - each ExaZK instance announces only one VIP, for whose this instance is authoritative (
auth_ipparameter) - each ExaZK instance writes down to ZK its health state, using an ephemeral node
group neighbors {
neighbor 172.28.128.11 {
router-id 172.28.128.1;
local-address 172.28.128.1;
local-as 65001;
peer-as 65011;
}
process exazk-apex {
run /exazk/exazk.py -sF daemon -c /exazk/check_local_nginx.sh -n apex -A 10.20.255.1 -N 10.20.255.2 -N 10.20.255.3 -zH localhost -zPS /exabgp/service/apex -zPM /exabgp/maintenance/apex;
}
}- when an instance dies, its ephemeral node in ZK goes with it. The other instances catch this event
- the other instances then announce the VIP of the faulty instance, until it comes back online.
A special mode, called maintenance, can be used to completely put a service offline: should an operator make this special node exists in ZK, the LBs would withdraw all the VIPs.
Last, a local check (same principle as used in healthcheck) allows every instance of ExaZK to check itself.
ExaZKis still under testing. If it’s of some interest to you, and you want to modify it to your needs, feel free to fork it on github !
Cheers !




